はじめに
こんにちは、lkjsxcです。
しばらく前の話になりますが、私は中学2年生の頃にGPT-3の存在を知り、とても大きな衝撃を受けました。
当時の私は、Scratch上で動作するプログラミング言語を趣味で作っていました。しかし、GPT-3を知ってから、関心の中心が一気にAIへ移りました。
もともと何かを自作することが好きだったので、自然とAIも自分で作ってみたいと思うようになりました。
しかし、現実はそう簡単ではありません。こだわりの強さ、集中力の波、資金不足、計算資源の不足、そして単純な実装力不足もあり、長い間、自分の手でそれらしいものを作るところまでは到達できませんでした。
大学2年になったこの春、(ChatGPTなどAIサービスへの課金が功を奏し、)ようやく自分の手元で、フルスクラッチのLLMとAIエージェントの形を作ることができました。
学習に使ったのは、自室の机の上にある、GeForce RTX 3070 8GBを積んだゲーミングPCです。
一般論として、LLMの開発には大きな計算資源が必要です。しかし今回使ったのは、特別なサーバーでも、クラウドGPUでもありません。2023年の春頃、中古市場に13万円弱で売られていたごく普通のゲーミングPCです。
その限られた環境で、ランダムな初期状態から小さな言語モデルを学習し、AIエージェントとして動く仕組みまでを作りました。
作ったもの
AIエージェントを、LLMからフルスクラッチで作りました。
github.com
ここでいう「フルスクラッチ」とは、既存のAIを改造したものではない、という意味です。公開されている基底モデルから追加学習したものでもありません。
ランダムなパラメータから、小さなデコーダ型Transformerを学習させ、そのモデルを中心にAIエージェントとして動く仕組みを作りました。
現在は次のような構成になっています。
RTX 3070 8GBで学習する、小さなフルスクラッチLLM
学習済みモデルを読み込むPython / PyTorch製の推論サーバー
推論サーバーを呼び出すRust製のWeb UI兼エージェント実行基盤
ファイル読み書き、シェル実行、Web取得、メモリ検索、メモリ書き込みなどのツール群
モデルがXML風のアクションを出力し、それをランタイムが検証して実行する仕組み
単に「質問を投げると文章が返ってくる」だけのものではありません。
モデルは、必要に応じてツールを選びます。
たとえば、ワークスペースの中身を確認するなら fs.list を呼び、ファイルを読むなら fs.read を呼び、記憶を検索するなら memory.search を呼びます。最後にユーザーへ返答するときは agent.finish を呼ぶ、という形です。
最初の構想では、JSONでアクションを出力させることを考えていました。
しかし、現在のlkjaiではXML風の形式を採用しています。
小さなモデルにとって、厳密なJSONを安定して出力し続けることは非常に難しいです。引用符、カンマ、エスケープ、括弧の対応など、破綻する場所が多すぎます。
そこで、現在は次のような設計にしています。
モデルには、短く、見通しのよい、1個だけのアクションを出してもらう。
そのアクションをRust側で検証し、問題なければツールを実行し、結果をまたモデルに返します。これを最大ステップ数まで繰り返します。
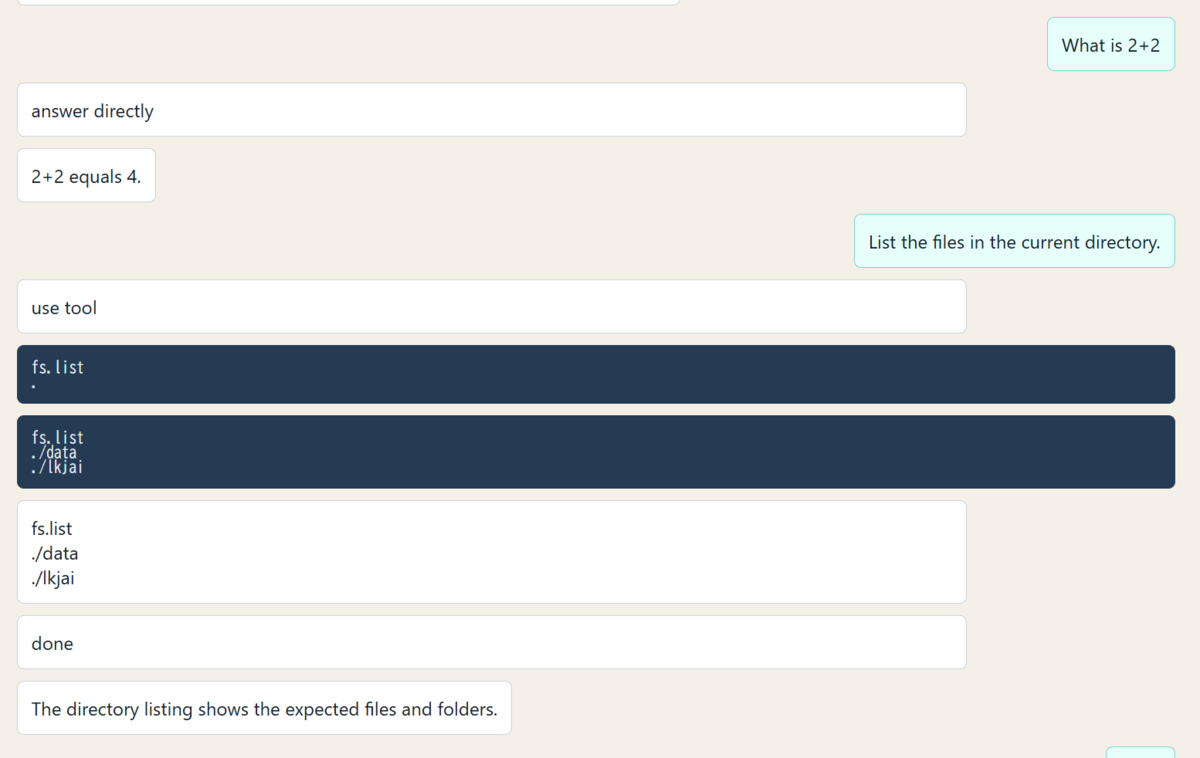
Web UIを開くと、ユーザーの発言、モデルの簡単な理由、ツール呼び出し、ツール結果、最終回答などが順番に表示されます。
見た目としては、かなりAIエージェントらしくなっています。
それらしい様子1
それらしい様子2
現実
しかし、残念ながらそう思うようには行きません。
現時点のlkjaiは、まだ実用的なAIエージェントではありません。
エージェントの器はできています。学習パイプラインもあります。推論サーバーも立ちます。Web UIも動きます。ツール呼び出しもできます。評価の仕組みもあります。
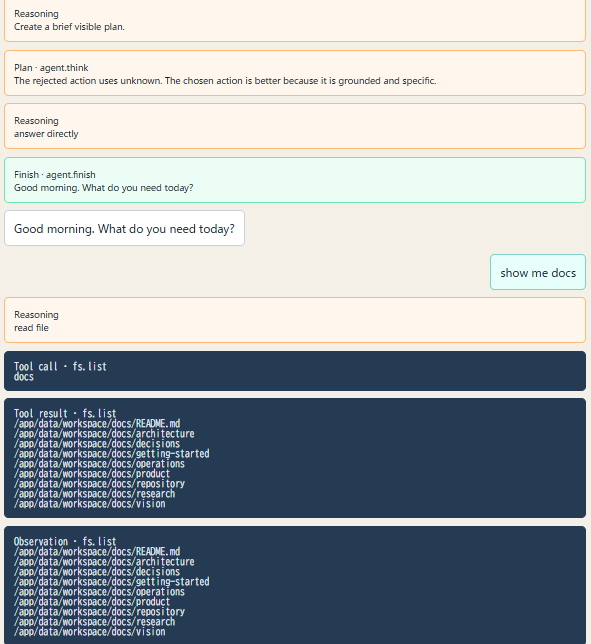
しかし、中心にいる小さなLLMが弱すぎる。
簡単な挨拶に対して、なぜか関係ないファイルを読みにいくことがあります。存在しないドキュメントを読もうとすることもあります。XML風の出力にはなっているのに、行動としては正しくない、というケースもあります。
だめそうな様子1
だめそうな様子2
しかし、そう悪いことでもないと考えています。
過去の私では、そもそもモデルを学習させ、推論し、エージェントとして評価するところまで到達できていませんでした。
ここまで来てようやく「まともに失敗できる場所」に立てた、という感覚があります。
これは、私にとって大きな前進です。
RTX 3070 8GB
今回の一番大きな制約は、やはりGPUでした。
ただし、RTX 3070が悪いという話ではありません。むしろ、よく動いてくれています。
このGPUは本来、ゲーム用途のGPUです。巨大なLLMを学習するためのものではありません。それでも、小さなTransformerを学習し、推論し、評価を回すところまでは問題なく付き合ってくれました。
問題は、LLMというもの自体があまりにも大きいことです。
現在のlkjaiのデフォルトモデルは、lkjai-scratch-40m です。名前の通り、およそ4000万パラメータのモデルです。
構成は次のようになっています。
語彙数:8192
コンテキスト長:1024
層数:10
hidden size:576
attention heads:8
KV heads:2
FFN size:1536
アーキテクチャとしては、RMSNorm、RoPE、Grouped-Query Attention、SwiGLU、tied embeddingsなど、現代的なLLMでよく使われる要素を素直に採用しています。
しかしながら、どれだけ現代的な要素を集めても、4000万パラメータはLLMとしては小さくなります。
現在広く使われている実用的なLLMは、数十億、数百億、数千億、あるいはそれ以上のパラメータを持ち、膨大なデータと計算資源によって学習されています。
それらと比べると、lkjai-scratch-40m は本当に小さいモデルです。
そして、フルスクラッチ学習では、より一層その小ささが厳しく現れます。
既存の基底モデルを使う場合、そのモデルはすでに大量の文章を読み、言語の基本、常識、指示追従などをある程度身につけています。
しかし、フルスクラッチでは違います。
最初のモデルは、ただの乱数です。最初は支離滅裂なトークン列を出すことしかできません。
さらに、RTX 3070に搭載されている8GBのVRAMに収めるためには、モデルサイズ、コンテキスト長、バッチサイズなど、さまざまな要素を削る必要があります。
ここしばらくの開発は、調査とトライアンドエラーの繰り返しでした。
アーキテクチャを見直す。出力が崩れたら教師データを見直す。評価を見直す。プロンプトを見直す。設定を変えてまた学習を回す。
最初は「RTX 3070でLLMを作る」という響きに面白さを感じていました。
今も、その面白さはあります。
ただし、それは「ありふれたゲーミングPCで、すごいAIができました」という派手なものではありません。
実際には、一日中聞こえてくるGPUファンの音をBGMに、学習ログと評価結果を見て、少しずつ原因を切り分けていく地味な作業です。
もちろん、vast.aiなどのクラウドサービスに課金し、H200のようなGPUを借りれば、開発速度は大幅に向上すると思います。より大きく、より賢いモデルも作りやすくなるでしょう。
それでも、自宅のゲーミングPCに縛って頑張ることには、独特の面白さ、ロマンがあります。
なぜフルスクラッチなのか
「わざわざゼロから作る意味があるのか」
これはかなり自然な疑問です。
実用的なAIエージェントを作りたいだけなら、公開されている強い基底モデルを使った方が確実です。
その方が圧倒的に賢いです。モデルによっては多言語も扱えます。ツール呼び出しも安定しています。コードも書けます。複雑な推論もできます。
わざわざRTX 3070で、小さなモデルを乱数から学習させる必要はありません。
しかしそれでも、私は確かめたかったのです。
自分の部屋にあるゲーミングPCだけで、限られた計算資源の中で、どこまで行けるのか。
このプロジェクトは実用性というより、好奇心に近い動機で進んでいます。
モデル
主な仕様は以下の通りです。
パラメータ数:約4000万
語彙数:8192
コンテキスト長:1024トークン
層数:10
hidden size:576
attention heads:8
KV heads:2
FFN size:1536
アーキテクチャ:RMSNorm、RoPE、Grouped-Query Attention、SwiGLU、tied embeddings
学習開始:ランダム初期化
モデルとしては、Llama系の現代的なデコーダモデルを、RTX 3070 8GBに収まるように小さくしたもの、と考えると分かりやすいと思います。
ただし、規模はまったく違います。
このモデルに、巨大なLLMのような知能は期待できません。
学習
学習は大きく分けて、次の2段階を想定しています。
causal_lm_full による通常の次トークン予測assistant_masked_sft によるXMLアクション形式の教師あり学習
前者では、公開コーパスの文章を使って、言語モデルとしての基本を学習させます。
現在の方針では、商用利用上の安全性も意識し、明示的に許容されたライセンスの公開データを使うことにしています。
後者では、lkjaiが実際に使うXML風アクション、ツール選択、メモリ操作などを学習させます。
ここで重要なのは、SFTではユーザー発話やシステム文ではなく、アシスタントの出力部分を中心に損失をかけることです。
モデルに「この文脈では、このアクションを出す」という対応を学ばせます。
エージェントループ
1回のユーザー入力に対して、lkjaiは次のように動きます。
ユーザー発話を記録する
直近の会話履歴を読む
古い履歴があればローリングサマリーを読む
関連する永続メモリを検索する
モデルサーバーが生きているか確認する
システム方針、ツール一覧、メモリ、最近の文脈をまとめてプロンプトを作る
モデルに1つのXML風アクションを出させる
そのアクションを検証する
reasoning があれば短い可視イベントとして表示するツールを実行する
結果を観察として追加する
agent.finish が出るか、最大ステップ数に達するまで繰り返す
最大ステップ数は、デフォルトでは6です。
モデルの出力が壊れていた場合は、修復を1回だけ試します。
同じ非終端アクションを繰り返した場合は、repeat_action として止めます。
この仕組み自体は、AIエージェントとしてはかなり一般的な構成です。
ただし、中心のモデルが弱いと普通に壊れます。
そして今は、まさにそこが主な問題になっています。
厳しい結果
テストの上では、lkjaiはまだ賢いとは言えません。
固定評価では、モデル、トークナイザ、エクスポート、設定など、成果物として必要なものが揃っているかを見ています。ここはかなり改善してきました。
一方で、実際にモデルを推論させ、正しい行動を取れるかを見るために設けたテストでは、まだほとんど通っていません。
直近の記録は 0/200 です。
つまり、200件のホールドアウトケースに対して、合格したものが0件でした。
これは厳しい結果です。最初に見たときは非常に落ち込みました。
しかし、少し冷静になると、これはある意味では妥当でもあります。
小さなモデルに対して、いきなり次のようなことを求めています。
挨拶なら余計なツールを呼ばずに返答する
ファイルが必要なら正しいツールを選ぶ
存在しないファイルを読もうとしない
失敗したツール呼び出しを同じまま繰り返さない
更新前には確認を要求する
XMLの形を壊さない
最後は agent.finish で終わる
人間から見ると簡単に見えます。
しかし、4000万パラメータのフルスクラッチなモデルにとっては、荷が重すぎました。
自宅のゲーミングPCで全部動かす
今回の開発で一番面白かったのは、自宅のPCで一通りの流れが完結していることでした。
学習も、推論も、Web UIも、評価も、自分の机の上で動きます。
lossが下がる。チェックポイントが保存される。推論サーバーが立ち上がる。Web UIからメッセージを送る。モデルが変なXMLを返す。それを見て、データやプロンプトや評価を直す。
この一連の流れには、クラウドのAPIを叩くだけでは得難い手触りがあります。
一方で、この計算機の限界もかなりはっきり見えました。
RTX 3070 8GBでは、できることとできないことの差がはっきりしています。
小さなモデルを学習することはできます。小さなモデルを推論することもできます。学習パイプラインを作り、評価を回し、改善サイクルを作ることもできます。
しかし、実用的で強い言語能力を持つモデルをフルスクラッチで作るには、圧倒的に足りません。
おそらく、このプロジェクトの本質はそこにあります。
「RTX 3070でもLLMを作れる」という話ではあります。
しかし、それ以上に、「RTX 3070で作ると、LLMの厳しさがよく分かる」という話でもあります。
今後
まず、教師データをより充実させ、XMLアクションの基礎を安定させます。
モデルが正しい形式を出せないなら、ツール実行以前の問題です。
まずは、短く、壊れていない、1個だけのアクションを出せるようにする必要があります。
その上で、ファイル読み取り、一覧取得、メモリ検索のような読み取り系ツールを順番に安定させます。
学習面では、公開事前学習コーパスと、first-partyなXMLアクションSFTコーパスをもっと丁寧に作り直す必要があります。
さらに、挨拶、短い質問、ツール不要の返答、ファイル操作、メモリ操作を分け、それぞれの評価も分ける。
そうしないと、どこが良くなったのか分かりません。
また、モデルサイズについて、将来的には200M前後のものにも興味があります。
しかしながら、モデルを大きくするとその分必要な計算量も増えます。
データや評価が悪いまま大きくしても、おそらくあまり意味がありません。
まずは個人で辿り着ける40Mの限界に挑むつもりです。
おわりに
中学2年生の春、GPT-3に衝撃を受け、AIに強い関心を持つようになりました。
そこから何度も試行錯誤して、今回ようやく、自分の手元でフルスクラッチなLLMとAIエージェントの形を作ることができました。
ただし、それは強いAIではありません。
テストも通りません。挨拶で変なツールを呼ぶことがあります。XMLも壊れます。簡単なベンチマークですら結果は散々です。
それでも、ランダムな重みから始めて、モデルを学習し、推論し、エージェントとして動かし、失敗を観測できるところまで来ました。
これは、自分にとって大きな一歩でした。
このプロジェクトは、まだ完成していません。
むしろ、ようやく本当のスタート地点に立ったくらいです。
おわりに2
この記事を書き終えてから気がついたのですが、今のモデルはまだ通算で50時間ほどしか学習していません。
自宅のGPUを回している体感としてはそれなりに長いのですが、LLMの学習として見ると、50時間はかなり短いです。
もちろん、ただ長く学習させれば急に賢くなる、という単純な話ではありません。データの質、学習率、SFTの作り方、評価設計など、見るべきところはまだたくさんあります。
それでも、数週間、あるいは数ヶ月単位で学習を続けたら、今より少しはまともな挙動になるのではないか、という期待はあります。
現在進行系で、自室のRTX3070は学習を続けています。
おわりに3
現状のlkjaiは、まだ実用的な段階にありません。
しかしながら、学習パイプライン、推論サーバー、Web UI、ツール実行、評価の仕組みまでは一通り揃ってきました。
つまり、あとは中心にいるモデルをどう育てるか、という話になりつつあります。
......ところでふと、全力機械株式会社様からご支援いただいた資金が、ありがたいことにまだいくらか残っていることに気が付きました。
来月はその資金を使って、TPUやクラウドGPUを借り、フルスクラッチにこだわらず、「実用的なAIエージェント」の開発に挑戦したいと考えています。
私のAIへの熱意は、もうしばらく冷めそうにありません。





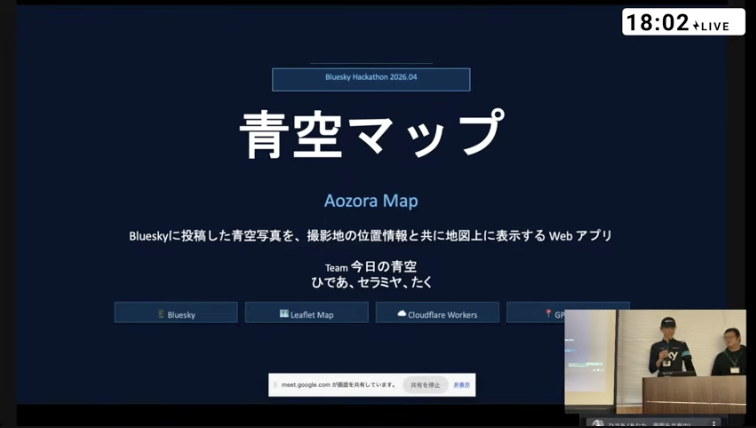
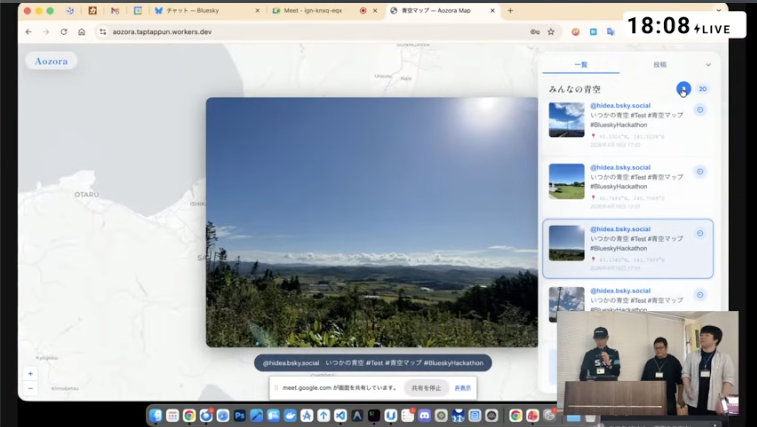 Blueskyに投稿される「青空」の写真が、どこで撮影されたものかをマップ上に可視化するアプリ。ダントツの1位でした!
Blueskyに投稿される「青空」の写真が、どこで撮影されたものかをマップ上に可視化するアプリ。ダントツの1位でした!



 自分の投稿を「本棚」のようにまとめて、後から見返しやすくするストック型サービス。
自分の投稿を「本棚」のようにまとめて、後から見返しやすくするストック型サービス。